Continuous validation. Drift detection. Release evidence.
Records deploys adjacent to your FHIR server and answers the question your CDR can't: “Is this data still conformant?” The answer becomes evidence for implementers, sponsors, auditors, and AI agents before they ship, route, or act on FHIR data.
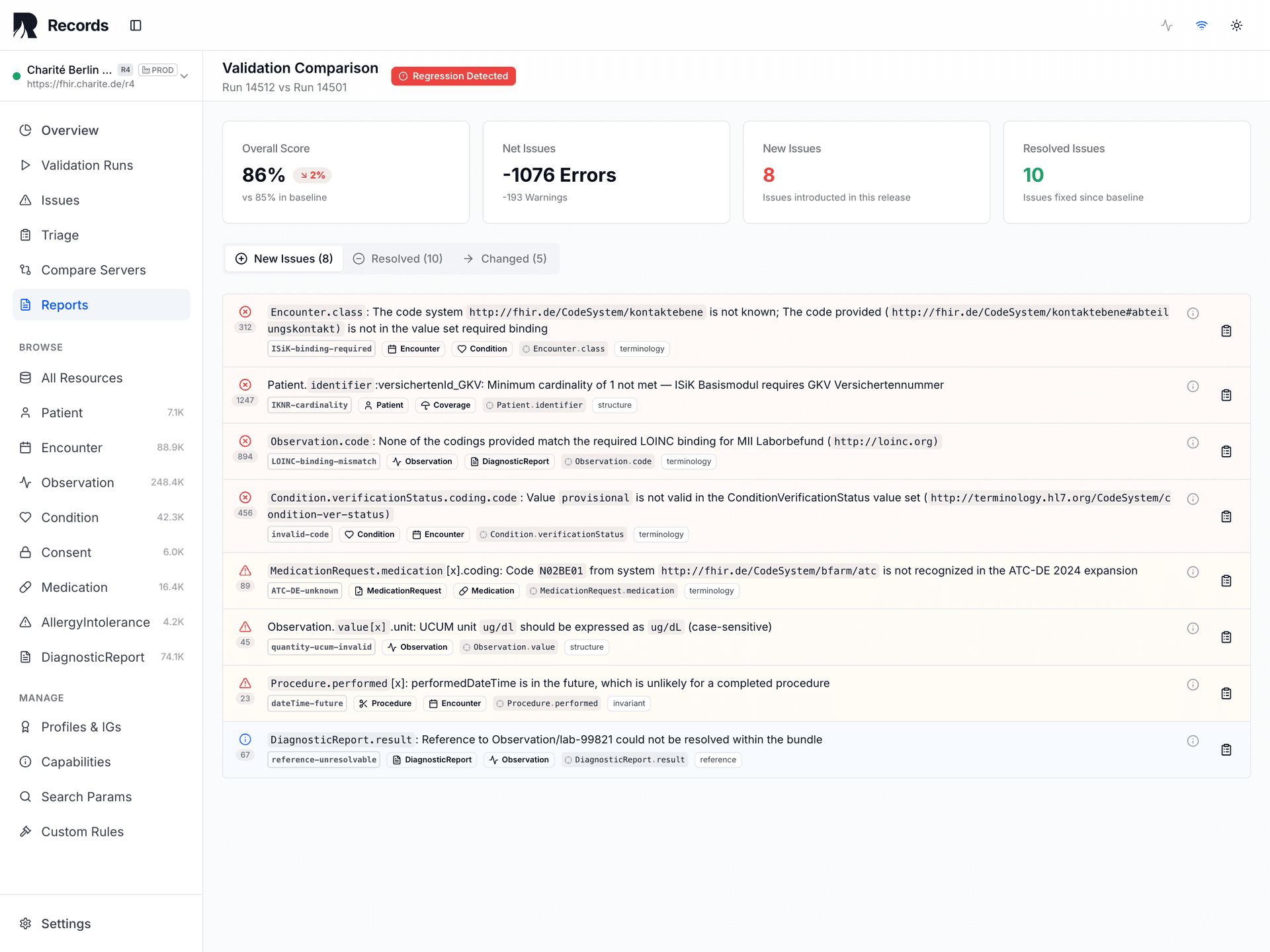
Release Safety Gate
Validate before pushing an IG/Profile update, FHIR server upgrade, or mapping change to production.
What Records does
Five things Records does for your FHIR infrastructure.
Validates continuously
Runs profiles, terminologies, and custom rules against live FHIR data. Every run produces a deterministic PASS / WARN / FAIL signal.
Detects drift
Compares each validation run against baselines. Surfaces regressions from server upgrades, profile revisions, terminology changes, and pipeline modifications.
Produces evidence
Generates reproducible, timestamped proof for release gates, regulatory submissions, compliance audits, and supplier acceptance.
Manages environments
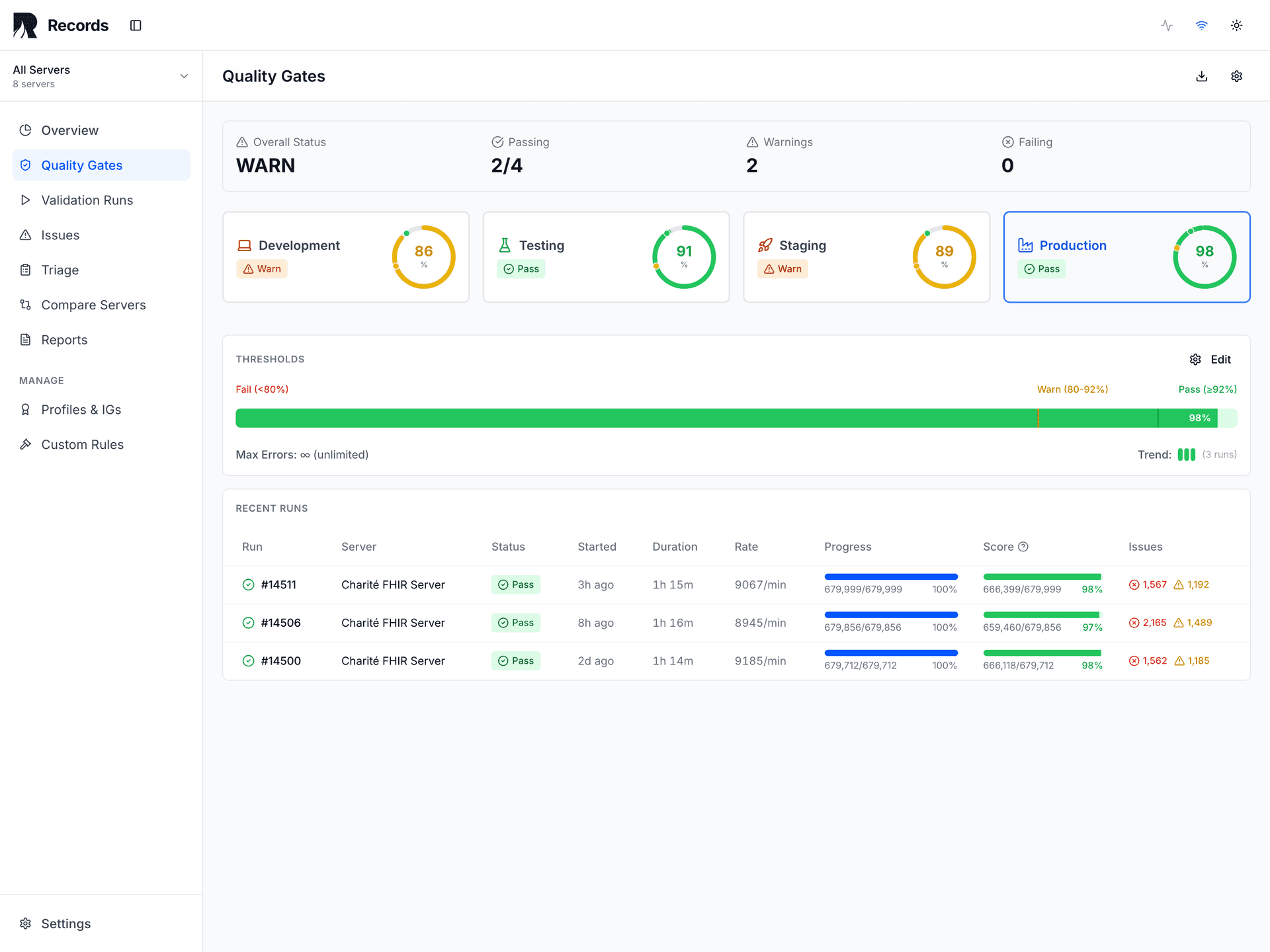
Tracks validation state across dev, staging, and production. Compare signals across environments before promoting changes.
Guards agentic workflows
Gives LLM agents and automation pipelines validation, terminology, quality-score, and run-comparison checks before they generate, transform, summarize, route, or act on FHIR data.
Deterministic Signals
Every validation run produces one of three signals. Records produces signals — you decide and act.
All thresholds met
Operator: proceed with confidence
Non-critical thresholds breached
Operator: proceed with investigation
Critical thresholds breached
Operator: investigate before proceeding
The reproducibility contract
These fields must be identical for a validation run to be considered strictly comparable. Given the same contract, Records produces the same results — today, next month, or during an audit three years later.
| Input | Why it matters |
|---|---|
| Validator tool + version | Engine identity and behavior determinism |
| Validator configuration | Strictness settings, enabled aspects, scope |
| IG packages + canonical pinning | Profile set, versions, and canonical URL resolution locked via .records-lock.json |
| Terminology source + snapshot | Resolves code bindings at a fixed point in time |
| Environment label | Isolation and comparison context |
| Thresholds applied | Pass/warn/fail criteria per aspect |
| Run timestamp | Point-in-time data snapshot |
| SHA-256 content hash | Tamper detection on every evidence report |
Canonical pinning eliminates a common source of silent validation drift: when multiple installed IG packages define the same canonical URL, the resolution order can change between installs. Records generates a .records-lock.json lockfile at install time that pins every canonical URL to a single, deterministic source. Same packages + same lockfile = same results.
Why evidence matters
The core diagnostic question is not “Is our data valid?” but “Will we know when it stops being valid?”
Conformance at deployment time proves nothing about conformance tomorrow. At least seven distinct drift vectors can silently degrade data quality after initial validation:
| Drift Vector | Example |
|---|---|
| Terminology server update | CodeSystem version change alters ValueSet memberships |
| IG/Profile revision | New constraints added or cardinality changed |
| FHIR server upgrade | HAPI v8.x upgrade changes validation behavior for certain edge cases |
| Mapping pipeline change | ETL logic drift alters output structure |
| Environment config divergence | Dev uses R4@1.4.0, Prod uses R4@1.5.0 |
| Data volume shift | Edge cases emerge at scale that never appeared in testing |
| Dependency chain update | Transitive profile dependency changes upstream |
Without continuous validation, these vectors compound silently. Records makes each one detectable.
How it fits your infrastructure
Records adds an observation layer. It doesn't build a silo.
Records IS
- • A validation control plane
- • A drift detection engine
- • A release evidence surface
- • An environment comparison tool
- • A vendor-neutral observer — independent TypeScript engine, no HAPI dependency in production
- • Adjacent to your existing stack
Records is NOT
- • A CDR or storage platform
- • An EHR or clinical application
- • A BI or analytics system
- • A compliance certification tool
- • A system of record
- • A decision-making authority
Clear responsibility boundaries
| Responsibility | FHIR Server / CDR | Records |
|---|---|---|
| Data storage | ||
| Data access control | ||
| Clinical workflows | ||
| Validation evidence | ||
| Drift detection | ||
| Release gates | ||
| Baseline management |
The engine
Pure TypeScript. No JVM. Built for speed, accuracy, and determinism.
Open source · v0.3.0 · Apache-2.0
The engine is yours to embed
The validation engine ships standalone as @records-fhir/validator on npm — the same code that powers Records, available for your own stack. No Records server required for local validation.
Performance
~5 ms
Median validation time
CPU-only, no I/O
100%
Recall
244/244 defects detected
8
Validation aspects
Incl. anomaly detection
~175/s
Engine throughput
CPU-only, no I/O (M1 Max)
Validation quality
244 of 244 known defects detected. Zero false negatives across 16 defect categories and 12 resource types.
Near-zero false positives. 100% precision on profiled data (ISiK, MII, UK Core). 99.5% on HL7 base examples.
Measured against a 610-fixture test corpus (244 defect + 187 clean + 179 profiled) covering Synthea, MII, ISiK, UK Core, and customer-reported edge cases.
8 validation aspects
| Structural | JSON/XML schema conformance, required fields, data types |
| Profile | StructureDefinition constraints, must-support, cardinality |
| Terminology | Code bindings, ValueSet membership, CodeSystem validity |
| Reference | Reference targets exist and resolve to correct types |
| Invariant | FHIRPath constraints defined in profiles and base spec |
| Custom Rules | Project-specific FHIRPath rules beyond standard profiles |
| Metadata | Resource metadata consistency, version, lastUpdated |
| Anomaly | Cross-resource statistical outliers, missing patterns, distribution skew, PII detection (DE: KVNR, Steuer-ID, IKNR, IBAN · US: SSN) |
Custom Rules & Advisor Rules
Define project-specific validation rules in FHIRPath — beyond what standard profiles cover. The built-in editor offers autocomplete for 40+ FHIRPath functions, interactive testing against sample resources, batch testing, templates for common patterns, rule versioning with rollback, and per-rule execution statistics. 15 example rules ship out of the box. Advisor Rules let you suppress, reclassify, or annotate validation issues post-validation — with import support for gematik Referenzvalidator YAML and Firely Quality Control formats.
What makes it different
Capabilities that go beyond single-resource validation.
Cross-resource anomaly detection
"90% of your Observations have effectiveDateTime. These 100 don't." 8 statistical detectors analyze patterns across your full dataset — no single-resource validator can do this.
Fix suggestions for every error
265 of 265 emitted error codes have actionable remediation steps with patch-style suggestions. Most validators cover 10-30%.
Pure TypeScript — no JVM
No Java, no .NET runtime. Instant startup. Runs anywhere Node.js runs — CI runners, Docker containers, edge environments.
Two-phase terminology
ValueSets expanded and cached locally at install time. Code lookups resolve in <1ms — not 50-200ms per round-trip to a remote terminology server.
Deterministic by design
Same inputs always produce the same outputs. The reproducibility contract pins every variable. Evidence is comparable across time and environments.
MCP server for AI agents
Built-in Model Context Protocol server exposes validation, issue explanation, quality scoring, and run comparison to agents that generate, transform, summarize, route, or inspect FHIR.
Records vs. standalone FHIR validators
| Capability | Standalone validators | Records |
|---|---|---|
| Single-resource validation | ||
| Dataset-level validation | resource-by-resource only | full dataset against all profiles |
| Cross-resource anomaly detection | 8 statistical detectors | |
| Fix suggestions | Partial (~10-30% of errors) | 100% of errors (265/265) |
| Cold start | ~10-20s (JVM / .NET) | ~1.3s (Node.js) |
| Warm validation | ~100-500ms per resource (JVM) | ~5ms per resource |
| Evidence reports | pass/fail per resource | 5 report types with SHA-256 integrity |
| Baseline & drift detection | Continuous delta comparison | |
| Regression tracking | Full history with per-issue lifecycle | |
| AI agent validation | Built-in MCP tools for validation, explanation, scores, and run comparison | |
| Runtime dependency | JVM or .NET | Node.js only — no JVM |
Standalone validators validate individual resources on demand. Records adds continuous monitoring, dataset-level analysis, and reproducible evidence on top of validation.
MCP server for AI agents
Records ships a Model Context Protocol (MCP) server that gives LLM clients (Claude, Cursor, and others) live access to the validation engine and project data — including runs, baselines, and quality history.
4 tools wired to the real validator
validate_resourceRun validation on a FHIR resource
explain_issueGet fix suggestions for a validation issue code
get_quality_scoreCurrent corpus quality metrics
compare_runsDelta between two validation runs
Distinct from the open-source surfaces: @records-fhir/validator embeds the engine in your code, and the Claude Code plugin runs validation locally inside Claude Code (MIT). The MCP server runs as part of Records, talks to your registered FHIR servers, and exposes live project state to agents.
Common Records use cases
Six scenarios where continuous validation turns into release, audit, and agent trust evidence.
Validate before every IG update, server upgrade, or mapping change hits production
Drift & RegressionDetect conformance drift from terminology updates, IG changes, and upstream system changes
Multi-Server ComparisonCompare conformance across servers, suppliers, and environments
Regulatory & Audit EvidenceProduce reproducible quality evidence for regulatory submissions and compliance audits
CI/CD Quality GateAdd FHIR validation to your GitHub Actions or GitLab CI pipeline
Agentic FHIR WorkflowsValidate agent-generated or transformed FHIR before downstream use
The Operating Model
Records operates continuously, not episodically. Validation runs on every change, not quarterly audits.
The release-safety loop is the core operational cycle:
Each step in the loop produces traceable evidence. Baselines establish known-good states. Runs produce signals. Deltas quantify change. Alerts notify. Triage assigns ownership. Fixes resolve. Re-baselining closes the loop and starts the next cycle. The operator controls every transition.
Issue lifecycle
Validation issues are not disposable alerts. Each issue is a persistent triage item with ownership, status, and an audit trail. Closure requires a passing verification run — you cannot mark an issue as resolved without evidence.
5 evidence report types
Run Report
Complete validation results for a single run — scores, issues, aspect breakdown.
Baseline Report
Snapshot of a known-good state. The reference point for all future comparisons.
Delta Report
What changed between two runs — new issues, resolved issues, score drift.
Release Report
Go/no-go evidence for a release gate. Aggregates runs, baselines, and deltas.
Dataset Quality Report
Cross-resource quality analysis across an entire FHIR dataset.
Every report carries a SHA-256 content hash for tamper detection. ID redaction replaces resource identifiers with deterministic hashes for safe external sharing with auditors and regulators.
Talk to us about Records.
Share your context, question, or integration idea. We'll help you identify the right next step.